Using Azure Data Factory with the Application Insights REST API
Persisting aggregates of monitoring data in a warehouse can be a useful means of distributing summary information around an organisation. It also makes sense from a cost perspective as you don't necessarily need to retain raw telemetry data over the long term.
The Application Insights REST API is a convenient way of retrieving metrics, events and queries on telemetry data. That said, it's not really designed for retrieving raw data is has some rate limits and a maximum of 500k results in each request.
If you want to get raw telemetry data out of AppInsights then you're better off looking at the continuous export feature. This output is extremely verbose and you'll need to use something like Stream Analytics to make any sense of it. You may end up paying to store a level of fidelity that you just don't need.
Azure Data Factory can be used to extract data from AppInsights on a schedule. To run a query against AppInsights in Azure Data Factory there are three main entities that you'll need to create:
- A REST linked service that defines the root URL for all your AppInsights requests
- A dataset that can be used for every AppInsights query
- A pipeline containing a copy activity that defines the query syntax and writes the output from AppInsights to your chosen destination
Creating the linked service
You can use a single linked service for every query to App Insights. All it does is define the base URL for your application. If you create a new linked service for a “REST” data store it will show the configuration screen below:

- Set the authentication type field to “Anonymous”
- You'll need to insert your application identifier in the Base URL field as part of the URL https://api.applicationinsights.io/v1/apps/{app-id}/
- Leave all the other settings as they are
Creating the dataset
You can define a single dataset that can be used across every query. This is because we don't need the know the schema of the result set when we connect to AppInsights – this is dealt with in the copy task's mapping in the pipeline.
Create a new dataset by selecting the “REST” data store. Enter a name and description and switch to the “Connection” tab shown below:

- Select your linked service
- Enter “query” into the relative URL field – this is the end-point for AppInsights queries.
Creating the pipeline
Each individual AppInsights query is defined in a separate pipeline with a single “Copy data” activity. This is where you define the query and the map the result set into a flattened JSON file.
Specifying the query
For this example, we'll just use a simple query that returns some a basic view of the availability tests, i.e.:
availabilityResults | project timestamp, name, success
The easiest way of sending a query with the AppInsights API is to use a POST method and embed the query in the request body. You can specify both the query and timespan using the following format:
{
"query": " availabilityResults | project timestamp, name, success",
"timespan": "PT12H"
}
Note that the query field must be a single line without any line breaks, which can be cumbersome for longer queries.
The timespan field can accept the following combination of ISO 8601 dates and timespans:
- The length of time before now (e.g P2D for the last 2 days)
- A start and end time e.g. 2016-03-01T13:00:00Z/20016-03-03T15:30:00Z
- A start time a length of time, e.g. 2016-03-01/P1D which specifies the time range covering the entire day.
Configuring the source
You specify the query in the copy task's sink as shown below:
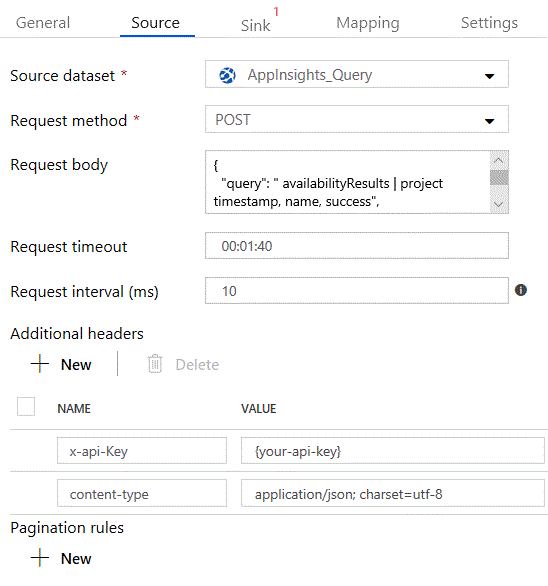
- Select the App Insights REST dataset that you set up in the previous step
- Set the request method field to “POST”
- Past the query into the Response body field
You will also need to add two headers:
- The “x-api-Key” header should contain the API key for your App Insights instance (how to generate an API key)
- The “content-type” header should be set to “application/json; charset=utf-8“
Configuring the sink
For this example, we'll write the output to a JSON file in Azure Data Lake Storage. This is straightforward to set up – you just need to create a connection to your ADLS instance and a data set that points to the file you want to write.
You can use the same data set for all your query outputs as you don't need to know the schema of your destination files. This will be defined using JSONPath statements in the copy task's mapping.
Configuring the mapping
Each App Insight query will return data in a hierarchical format. This is tricky to work with as the results are represented by a nested array as shown below:
{
"tables": [
{
"name": "PrimaryResult",
"columns": [
{
"name": "timestamp",
"type": "datetime"
},
{
"name": "name",
"type": "string"
},
{
"name": "success",
"type": "string"
}
],
"rows": [
[
"2019-10-28T10:07:46.701349Z",
"MyService",
"1"
],
[
"2019-10-28T10:07:41.586129Z",
"MyService",
"1"
],
[
"2019-10-28T10:08:36.1531113Z",
"MyService",
"1"
]
]
}
]
}
Ideally you'll want to flatten this before writing it to the sink. This can be done with a mapping that uses JsonPATH to specify the nested array. You set this up in the advanced mapping editor as shown below:
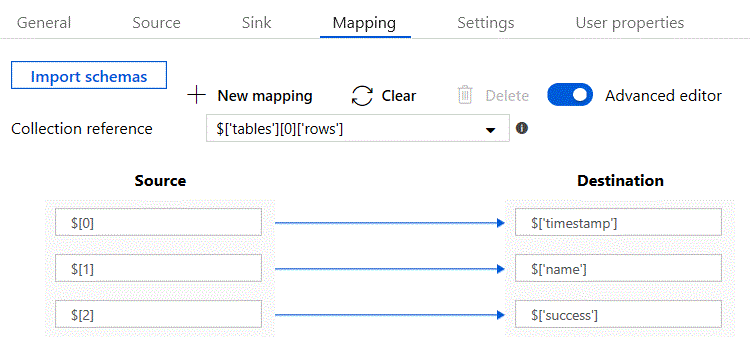
When you switch the advanced editor on you get more direct control over the way that fields are mapped.
- The results array is specified as $[‘tables’][0][‘rows’]
- You add mapped columns by clicking on the “New mapping” button
- Each individual field in the source can be identified as $[0], $[1] and so on
- You can map these fields to named fields in the sink using the format $[‘field-name']
This should be all you need to automate queries from App Insights. You may find it easiest to drop the query results into a data lake in the first instance without doing anything to transform the data. You can use downstream processes to aggregate it and put it into a format that is easier to query, such as a SQL database.